Data Science Final Project Second Blog Post
Diane Mutako, Hyun Choi, Leon Lei, Raymond Cao | April 19, 2019
Team m a c h i n e l e a r n i n g is back for some round 2 updates!
We heard this post was optional now, but that’s not how our team rolls. We’re going to keep this nice and brief and showcase some of the results we have so far. We still have a lot to get to, but as of now we have some updates on our progress in data processing, machine learning, and data visualization.
Data processing
We’ve made great progress in data processing. While originally a large roadblock, we mostly have this under control now.
Machine Learning
K-Means Analysis of Internet Provider Availability in the State of New York (2015)
This code performs an analysis of groupings of municipalities by number of internet service providers available through K-Means. We represented each municipality as a vector of length 5:
[ # cable providers, # dsl providers, # fiber providers, # wireless providers, # satellite providers ]Hypotheses and Beginning Thoughts
We originally thought that there would be 2 main clusters: one that consisted of rural households that had access to few internet service providers, and one that consisted of urban and suburban households that had access to many more providers. We also expected that the number of people in the former cluster would outnumber the people in the latter cluster.
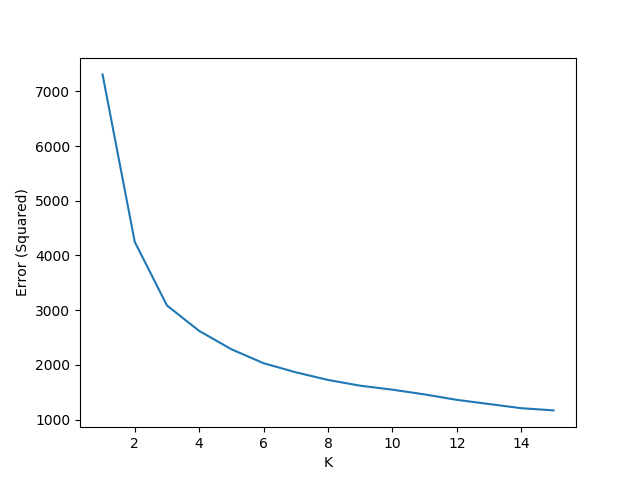
Finding K
To find the ideal value of K to perform the K-Means analysis, we plotted the errors (inertia) for values of K from 1 to 15 (inclusive) and found that 4 was best value as shown below.
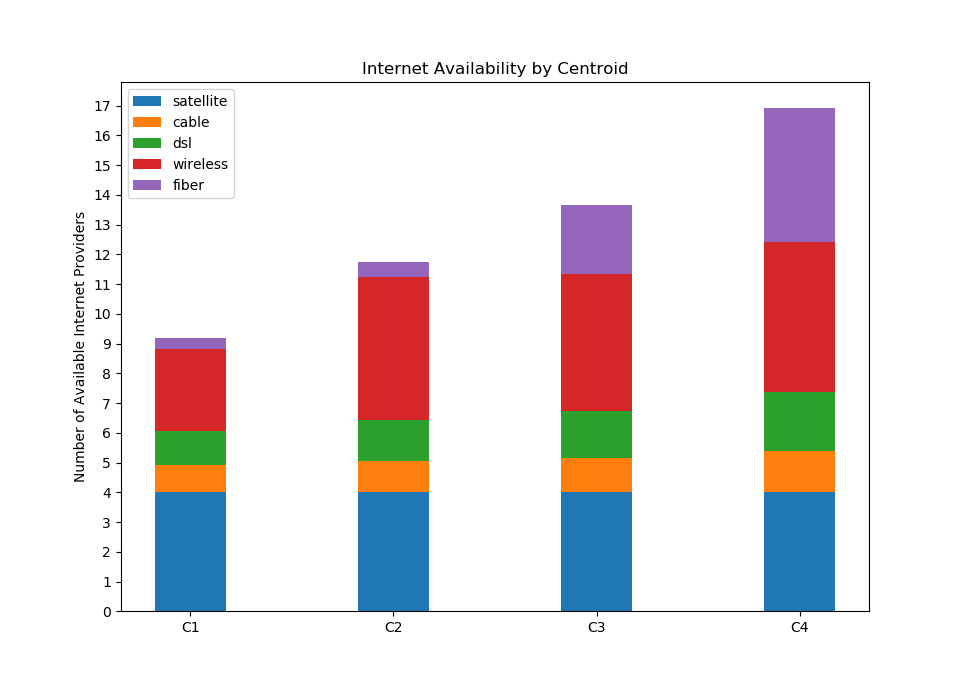
K-Means Analysis
With
K=4, we ran K-Means analysis 1000 times, and we found that the averages of the 4 centroids were the following (each row is a centroid):cable dsl fiber wireless satellite [[0.92470371 1.13378801 0.34721665 2.79396034 4. ] [1.05091665 1.37298036 0.50663221 4.86298947 4. ] [1.17256513 1.55794908 2.29653245 4.57346084 4. ] [1.38594809 1.99346829 4.49734056 5.04028195 4. ]]
Satellite seemed to have no significance, which made sense because it, by nature of the technology, is not heavily impacted by geography.
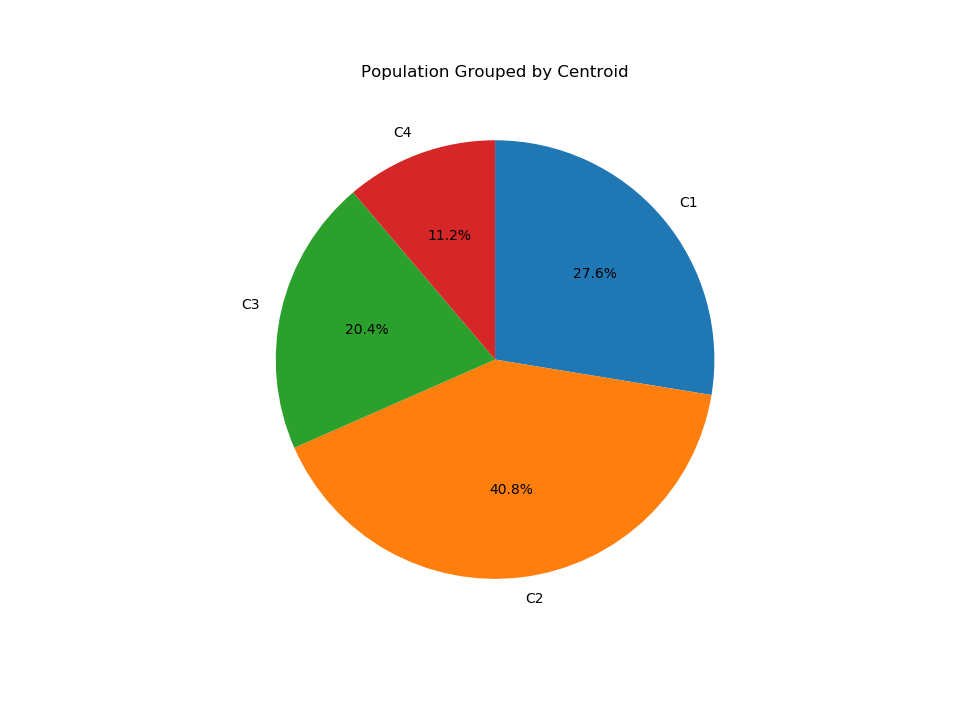
We also plotted a pie chart to see how many municipalities were grouped with each of the centroids. Each secion (shown below) from the top clockwise correspond to the centroids (shown above) from left to right.
Conclusions
Our first hypothesis was disproved in this analysis because there turned out to be 4 cluster rather than 2. While there were more people in the clusters with fewer provider choices, we were also surprised to see that the largest cluster was the one with the second-least number of choices.
The main thing that distinguished the two clusters with the least number of internet service providers was the number of wireless providers available. The largest group turned out to have more wireless choices – in fact, it has the second-most number of choices. Considering that this large cluster had almost no fiber internet providers available, this may suggest that te presence of a robust wireless network (which 5G may move towards) may discourage the development of faster, more costly networks like fiber.
Data Source
The data used to perform this analysis was downloaded as a CSV from these sources:
Data Visualization
We built a mini-framework for visualizing our data in scatterplot format, and this can eventually be extended to support other types of visualizations. As it stands now, our plot can easily be made interactive and allow users to choose which columns to sizeBy, colorBy, and which columns to use for the X-axis and Y-axis. The plot has zooming capabilities that take advantage of D3 Brush, and hovering over a datapoint will reveal some information about it.
Click here to view the visualization!!!
That’s it for now, see y’all at the next checkpoint! May all your connections be 4g or higher :)
team m a c h i n e l e a r n i n g, signing off ~